

10 Critical Kubernetes Tools and How to Debug Them
Kubernetes is both revolutionary and “diffusionary.” It is a complete restructuring demanding a whole new slew of companion and support tools to cover and prop up the entire ecosystem. There are literally hundreds of tools – both open-source and proprietary – designed specifically with k8s in mind.
Choosing your Kubernetes tech stack seems arduous – the ecosystem is huge. A comprehensive list of all the tools and their debugging methods is beyond the scope of this particular article. Developer-first observability demands simplifying this cacophony of tools. Getting a complete picture of and debugging your Kubernetes deployment requires an overarching tool and strategy that can be more direct and efficient than working through every single tool in the stack. With that being said, most individual tools provide internal observability. Knowing how to get those can give you an advantage as a developer.
It is impossible to create an exhaustive introduction to every kind of Kubernetes tool, but this list will cover the most fundamental ones of the major essentials and the major players in each of those categories.
Debugging K8S Service Meshes & Ingress Controllers
We already have orchestration and deployment tools, so why do we need something that sounds redundant? This gets to the crux of Kubernetes coordination between microservices. Service meshes and ingress controllers serve as configurable abstraction layers to control the flow of traffic in, and out, and within Kubernetes.
Service meshes coordinate between services within Kubernetes (i.e., east-west traffic).
Ingress controllers coordinate traffic flowing into (ingress) [and possibly out of (egress)] Kubernetes (i.e., north-south traffic). In Kubernetes, you would use the Kubernetes API to configure and deploy them. They:
- Accept ingress (incoming) traffic and route it to pods by load balancing
- Monitor pods and auto-update load balancing rules
- Manage egress (outgoing) traffic communicating with services outside the cluster
It’s debatable if you really need both of these kinds of tools for your Kubernetes stack, so in effect all the tools in the two categories are competing with one another. Additionally, you can also throw API Gateways into the mix here, which like ingress controllers might control ingress traffic and egress traffic.
The three major service meshes are Istio, Linkerd, and Consul. They use a “control plane” managing cluster-level data traffic and a “data plane” to deal directly with functions processing data between services within the mesh.
1. Debugging Istio
You can get a good overview of traffic in your Istio mesh with either of these two commands:
istioctl proxy-statusistioctl proxy-configYou can also go through the debug logs. Note that debug is one of five possible outputs for Istio logs (the others are none, error, warn, and info). Please know that debug will provide the most data, and some devs see Istio as pretty info-heavy when it comes to logs.
The following example defines different scopes to analyze:
istioctl analyze --log_output_level klog:debug,installer:debug,validation:debug,validationController:debug2. Debugging in Linkerd
The default method for debugging is using a debug container (a debug sidecar). However, Linkerd debugging works differently depending on the kind of application you’re using.
For instance, you would use metrics to debug HTTP apps and request tracing for gRPC apps.
- Debugging 502s, i.e. bad gateway responses
- Debugging control plane endpoints
- Debug HTTP apps with metrics
- Debug gRPC apps with request tracing
For Linkerd debug containers/sidecars:
kubectl -n <appname> get deploy/<appservicename> -o yaml \
| linkerd inject --enable-debug-sidecar - \
| kubectl apply -f -3. Debugging in Consul
Consul debug commands are extremely simple in Consul. Use -capture to define what you want to analyze, plus add in arguments for intervals, duration, APIs, the Go pprof package, and more.
consul debug -capture agent -capture host -capture logs -capture metrics -capture members -capture pprof -interval=30s -duration=2m -httpaddr=126.0.0.1:85004. NGINX Ingress Controller
NGINX is interesting because it’s easy to mix up what it dubs two separate tools: the NGINX Ingress Controller and the NGINX Service Mesh. This section looks at the ingress controller. To get a feel for how NGINX situates the two tools, their architecture diagram helps a lot:
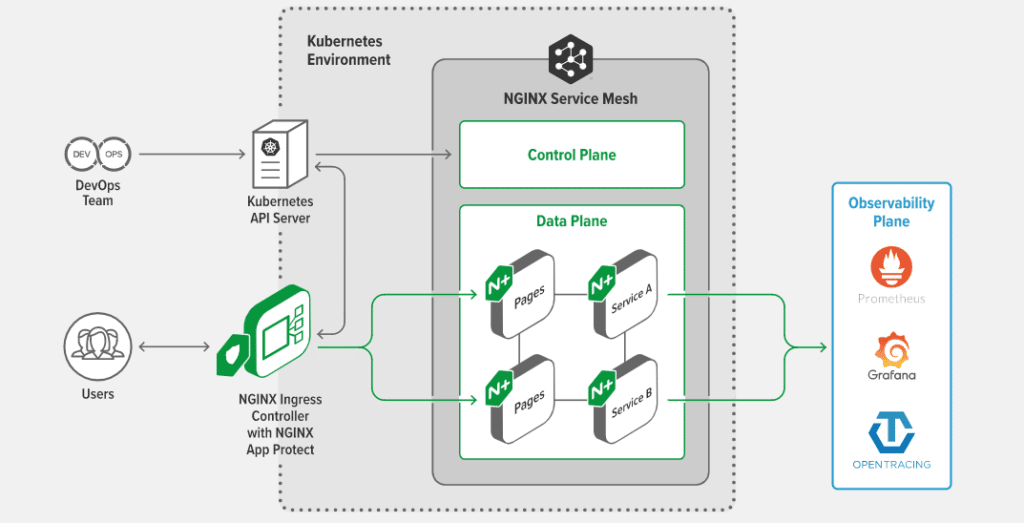
There are two types of logs you can cover here: for the NGINX ingress controller itself, and/or the more powerful overall NGINX logs.
Debugging with NGINX Ingress Logs
You can change the log level to debug by adding –v=5 to the -args section of your Kubernetes deployment. Please note that an NGINX deployment must be built with –-with-debug to have debug logs later.
kubectl edit deployment nginx-ingress-controller spec:
containers:
- args:
- /nginx-ingress-controller
- --v=5Debugging with General NGINX Error Logs
When you configure NGINX logging, you have to set up error logs, which are the most important for debugging.
But before you do that, you need to make sure NGINX (if working with the open source version) is compiled with the option to debug in the first place (yeah, this feels unnecessary, but that’s the way things are for now, as NGINX tries to manage how much it commits to storing logging data. Of course, the option could just be off by default, but we don’t live in that alternate reality).
First, download the open-source version of NGINX. Then begin the compiling process.
nginx -V 2>&1 | grep argumentsAdd the –with-debug parameter
./configure --with-debugCompile:
sudo makeInstall:
sudo make installAnd restart.
Now, phase 2. Double-check that the installation came –with-debug available:
nginx -V 2>&1 | grep -- '--with-debug'Open the NGINX config file:
sudo vi /etc/nginx/nginx.confAnd set the debug parameter:
error_log /var/log/nginx/error.log debug;There are more options available in the NGINX docs. As one last thing, I’ll add you can also use Syslog as an alternative, which requires a syslog: prefix, then designating a server (by IP, UNIX socket, or a domain).
error_log syslog:server=130.78.244.101 debug;
access_log syslog:server=130.78.244.102 severity=debug;5. Debug in Traefik (Ingress Controller)
The Traefik Kubernetes Ingress controller is another ingress controller option. It manages Kubernetes cluster services; that is to say, it manages access to cluster services by supporting the Ingress specification. Don’t mix it up with the company’s other tools: the Traefik Mesh and Traefik Gateway.
Like NGINX, you can set both/either Traefik Ingress logs and/or general Traefik logs and debugs.
Traefik Debug Logs
You can configure either debug-level Traefik logs or debugging through the Traefix API debugs. Both can be done in one of these three ways: through the Traefik CLI, a .yaml config file, or a .toml configuration file.
Log-wise, it’s a quick three-step process: 1. Set the filepath. 2. Set the format (json or text). 3. Set the level. This example shows how to do it in the Traefik CLI, but you can also use YAML or TOML config files.
--log.filePath=/path/to/traefik.log
--log.format=json
--log.level=DEBUGDEBUG is one of six log levels in Traefik, but the default is ERROR (the others are PANIC, FATAL, WARN, and INFO).
Traefix API Debugging
In the CLI, set up the API:
--api=trueThen you will have different config options for Kubernetes and other container orchestrators or infrastructure managers (Docker Swarm, Docker, etc.). Of course, let’s show a Kubernetes CRD example (in YAML), based on the one from Traefik docs:
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: traefik-dashboard
spec:
routes:
- match: Host(`traefik.progress-regress-we-all-scream-4-ingress.com`) <em>#this is clearly an example please do not visit this url and take no responsibility if it is real and unsafe</em>
kind: Rule
services:
- name: api@internal
kind: TraefikService
middlewares:
- name: auth
---
apiVersion: traefik.containo.us/v1alpha1
kind: Middleware
metadata:
name: auth
spec:
basicAuth:
secret: someFancyShmancySecretiveIngressiveSecretNameShorterThanThisThen set it to debug in the CLI:
--api.debug=trueDebug Kubernetes Tools for Infrastructure Management
Package Managers, Infrastructure-as-Code, configuration managers, automation engines, etc. This is a rather eclectic category because a lot of competing tools take different approaches to the same tasks, sometimes resulting not in direct competition but in complementary tooling.
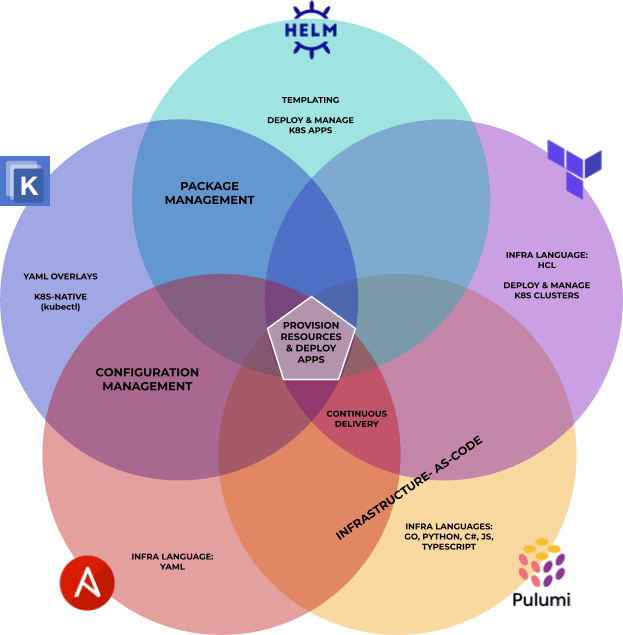
As such, many of these tools might be able to serve a purpose that the other tools on the list can’t. At the same time, while you can usually extend them to complete other kinds of tasks, it might be very difficult compared to one of the alternatives. Because of that overlapping, Kubernetes architecture diagrams can look like Frankenstein apps.
| Helm | Ansible | Terraform | Pulumi | Kustomize | |
| Main tool identity | Package Manager | Config managemen | Infrastructure-as-Code | Infrastructure-as-Code | Config management |
| Config management | Yes | Yes | No | Yes | Yes |
| Resource provisioning | Yes* | Yes | Yes | Yes | Yes* |
| Package manager | Yes | No | No | No | Yes |
| Application Deployment | Yes | Yes | Yes*** | Yes | Yes** |
* in combination with CrossPlane, Helm and Kustomize can provision cloud resources ** </span><span style="font-weight: 400;">kubectl apply -k</span><span style="font-weight: 400;"> (docs) *** when you provision K8S resources with terraform provider is actually deploy
Still, each use case is different. No matter which or how many of these tools you end up using, you should know where and how to debug them.
With Pulumi, you can write – or define – your infrastructure with fully-fledged programming languages: Go, Python, C#, vanilla JS, and TypeScript. Terraform uses HCL to define infrastructure and then a JSON state file to track it. Ansible though uses YAML to define infrastructure and is inherently stateless. The options expand from there.
6. Debugging Helm
Helm has become the de facto Kubernetes package manager for a lot of people. It utilizes complex templates for Kubernetes deployments that it calls Helm Charts. Templating or building out charts for deployment is a process in and of itself. There are a few ways to debug Helm templates.
The –debug Flag
Firstly, check what templates you’ve already installed:
helm get manifestThen let the server render the templates and return the manifest with it:
helm install --dry-run --debugOr…
helm template -debugYou can also use the –debug flag with most other other commands as well. It delivers a more verbose log response for whatever you’re doing. You can defer those logs to a specific file as such:
helm test -f -debug > debuglogs.yaml7. Debugging Terraform –
Terraform isn’t natively designed for Kubernetes, but it’s become a prevalent option. Terraform uses a system of support packages it dubs providers, and has constructed its own Kubernetes provider. It uses the HashiCorp Configuration Language (HCL) to deploy and manage Kubernetes resources, clusters, APIs, and more.
Alternatively, you might prefer to work through a provider like hashicorp/helm, which is more powerful than the vanilla Kubernetes option. You can use Terraform logs to one of several log levels, including debug. There are also specific strategies for debugging Terraform providers, or plugin integrations.
Terraform Debug Logs
You can log Terraform itself with TF_LOG or TF_LOG_CORE, or Terraform and all providers with TF_LOG_PROVIDER. You can extend the log setting to only one specific provider with TF_LOG_PROVIDER_<providername>.
TF_LOG_PROVIDER=DEBUGOptionally, you can use stderr for logging, but you cannot use stdout in Terraform as it’s a dedicated channel already.
You can use the native tflog package for structured logging, then set the log level. Depending on whether you’re using the framework or SDK Terraform plugin, you can set what contexts create debug logs. Consider the following example from the Terraform docs:
apiContext := tflog.SetField(ctx, "url", "https://www.example.com/my/endpoint")
tflog.Debug(ctx, "Calling database")
tflog.Debug(apiContext, "Calling API")8. Debugging Kustomize
You might have guessed from the spelling that this one is Kubernetes-native. Kustomize is a configuration manager, getting its name from customizing config files. Instead of relying on templating like Helm, it prefers to work strictly with YAML files, even using YAML files to configure other YAML files.
Now, for anyone who wants to debug Kustomize itself, independent of kubectl and other elements, it’s more complicated. Sort of like looking for mentions of Hell in the Old Testament, it’s impossible to find any documentation on logging, tracing, and especially debugging for Kustomize itself. There have been demands for logs pertaining strictly to Kustomize for sometime, but there are workarounds.
You can work the log_level as debug within your deployment.yml file inside your app.
env:
- name: LOG_LEVEL
value: "DEBUG"Afterwards, you would add your kustomization.yml file, delete your original resources and then redeploy the application.
9. Debugging Ansible
You have to enable the debugging setting, which is off by default. Next, you can utilize the debugger keyword, as in this example from the Ansible docs:
- name: Execute a command
ansible.builtin.command: "false"
debugger: on_failedEnable it globally in the ansible.cfg file in the [defaults] section:
[defaults]
enable_task_debugger = True10. Debugging Pulumi
Pulumi is one of the newer kids on the block, primarily an IaC tool. It works by exposing the Kubernetes API as an SDK to deploy and then manage IaC with containers and Kubernetes clusters among the infrastructures it works for. That being said, Pulumi tries to work with tools already widespread in the ecosystem, so it utilizes TF_LOG and its rules just as in Terraform.
Pulumi also has native log configuration, which can operate in regular programming languages instead of a CLI/domain-specific language. This example covers Java:
Additionally, you can implement the Pulumi Debug API. Pulumi’s docs use this multiple-choice style example with different options listed in the parameters:
debug(msg: string, resource?: resourceTypes.Resource, streamId?: undefined | number, ephemeral?: undefined | false | true): Promise<void>Debugging Kubernetes Tools is an Adventure
Each Kubernetes tool has more than one way to debug its services and implementations. Some have different approaches to debug logs while others include trace collection as options. Developer-first observability would demand you find the options that provide the clearest answers and easiest setup. There is also the probability some competing tools can cooperate within the same Kubernetes stack. Hopefully, this overview gives you a sense of what’s out there, and which tools you’d want to use for Kubernetes debugging.
But getting a true overview of what’s going on throughout your Kubernetes stack requires a truly overarching tool. Rookout prioritizes developer-first observability, easing that Kubernetes debugging and observability adventure. Rookout lets you debug multiple instances simultaneously, identify what clusters need your attention, and visualize your containerized application’s mapping. The Rookout SDK can work with all the major Kubernetes engines at the code level: GKE, AKS, and AWS EKS. Check out our tutorial for debugging Kubernetes on the fly and subscribe to our newsletter for more updates.
Related posts



